(♡)
Markdown to HTML Complier in C
Jump to the beginning Now that this project is completed, I'll be putting new notes at the top7/22/2020 - HR
Just added HRs! Another 5 minute process. I've also added a special search term to easy find where I need to update the code. There are 6 places.7/21/2020 - Bullets
Just added bullets! I love this system so much.. It felt like a 3 minute process to add a first pass at some simple bullets. What's great about this, is there is no pressure to get it perfect the first time. I'll be able to modify the design as much as I want. I've also been thinking about making the navigation have multiple levels of hierarchy so h2 tags are also represented there - that would be a snap to do.7/8/2020 - New Ideas
My brain is lit up with new ideas for how I can extend this system to have completely new concepts. For example: What if there is a way to put private notes in these files? That way, I can use it for my own personal notes, and make public the parts that I find relevant. Also, I realize that in practice I usually have the most recent stuff at the top, and the oldest stuff at the bottom of text files - much easier that way. I wonder if that makes sense for this project.Start Here
This website is written in a markdown-like language, parsed with c, and output in html. Markdown Compiler - source code Why? Well, for fun and learning of course! But also, it kind of is more sensical than a static website, that has to be completely reparsed by an interpreted language every time each user accesses the site. I am implementing the idea of "series" - which is basically a collection of linked articles, in a kind of blog-like format. On all projects I like to adhere to as much of a Data Oriented approach as possible. So let's establish what our inputs and outputs are.
Inputs:
Directory -> Text files in markdown format
Outputs:
HTML
A question for me that pops up at this point, is how I'm often benefited by an intermediate step in between, that looks more like this:
Raw Data -> Processed Data -> Output Data
While this extra step means I have to loop through the data twice (on both arrows "->"), it means that I'm able to deal with a much more clear dataset when I produce output. So we'll see if that's what I do on this project, I'm not sure yet.
Also a point that pops up for me, is that it may be more accurate to show the individual steps of gathering data.
Like this:
Directory Name -> Array Of All Files Array of All files -> Markdown Markdown -> HTMLAnd then I take pause to think, would Mike Acton be happy with me now? ... On second though, It's best not to ask yourself if Mike Acton would be happy with you now. Let's proceed.
Day 1 - Finding filenames
opendir nicely fits this purpose - it takes a folder name, and politely spits back all files and sub directory names. So perhaps this changes our input/output diagram a bit:Root Directory Name -> Root Filenames + Sub Directory Names Sub Direcotory Names -> Sub Directory Filenames...A few hours later. Okay the problem seems best represented like this:
Root Directory Name -> All Directory Names
All Directory Names -> array of {directory_name, file_name}
First we get all directory names:
void get_all_dir_names(char dirs[DIR_ARR_MAX][DIR_NAME_MAX], int * dirs_count) {
DIR * dir_handle;
dir_handle = opendir("./series");
assert(dir_handle);
*dirs_count = 0;
struct dirent *entry;
// add root name
char dir_prefix[] = "./series/";
strcpy(dirs[*dirs_count], dir_prefix);
int dir_prefix_len = strlen(dir_prefix);
*dirs_count += 1;
char dir_name[DIR_NAME_MAX];
while ((entry = readdir(dir_handle)) != NULL) {
if (entry->d_type == FileType_dir) {
if (strcmp(entry->d_name, ".") == 0) continue;
if (strcmp(entry->d_name, "..") == 0) continue;
assert_d(*dirs_count < DIR_ARR_MAX, *dirs_count);
int dir_name_len = strlen(entry->d_name) + dir_prefix_len;
assert_d(dir_name_len < DIR_NAME_MAX, dir_name_len);
sprintf(dir_name, "%s%s", dir_prefix, entry->d_name);
strcpy(dirs[*dirs_count], dir_name);
*dirs_count += 1;
}
}
closedir(dir_handle);
}
Then we get all files in all the directories:
void get_all_files_in_dirs(
char dirs[DIR_ARR_MAX][DIR_NAME_MAX],
int dirs_count,
File files[FILE_ARR_MAX],
int * files_count)
{
*files_count = 0;
struct dirent *entry;
for (int dir_idx = 0; dir_idx < dirs_count;++dir_idx) {
char * dir_name = (char *)&dirs[dir_idx];
DIR * dir_handle = opendir(dir_name);
assert_s(dir_handle, dir_name);
while ((entry = readdir(dir_handle)) != NULL) {
if (entry->d_type == FileType_file) {
File * file = &files[*files_count];
char * file_name = entry->d_name;
assert_d(*files_count < FILE_ARR_MAX, *files_count);
assert_s(strlen(dir_name) < DIR_NAME_MAX, dir_name);
assert_s(strlen(file_name) < FILE_NAME_MAX, file_name);
strcpy(file->dir_name, dir_name);
strcpy(file->file_name, file_name);
*files_count += 1;
}
}
}
}
While this does iterate through the root folder files twice, I accept trading the tiniest bit performance, for a good deal more clarity and debuggability.
RETROSPECTIVE NOTES 7/3/2020
All this code ends up being unused, because as I sprinted to finish this project, the idea of automating this aspect of file discovery was simply not practical.
I needed more control over everything.
The big lesson here for me, was this: Start with the Inside First
Day 2 - Scanning files
The next step:
Input:
Raw files
Output:
File Structure
Throughout this process, I'm really seeing the benefits behind using data tranformation as the model of what we're doing. That's all it is, I have data in one state, and I'm moving it to another state. There's no need for anything extra.
I'm getting comfortable with how the code should look, so I'll write out the funciton call first:
Page pages[PAGE_ARR_MAX];
int pages_count;
get_all_pages_from_file_names(file_names, file_names_count, pages, &pages_count);
From this I'll get a structure of files - this is similar to what I've done on this site before, but I'm feeling like writing it from scratch because I've gotten a lot better at solving the problem of file parsing, with some of my experience writing a compiler.
First lesson of the day: Moved some code around, created a seg fault. Turned out it was because I was copying to an array, but the array's index was not yet initialized.
This is because I decided to put the initialization inside the function, which makes sense, but maybe it would just be better to put it outside the function and assert that it is zero when you enter the function.
It's a little weird, asserting when I could just do the thing that I'm asserting about, but I think I'll be more careful about moving an assert about than I will about moving an assignment operation about. This is definitely a downside.. or lets say a challenge of C.
It really challenges me to write safe code where I'm always in control and on top of what's going on. Asserts are the backbone of confidence in code.
Asserts are like little unit tests, if unit tests did what they promised to do and took much less effort.
God I love hating on Unit Tests. Maybe too much.. Back to coding.
void get_all_pages_from_file_names(FileName file_names[FILE_NAME_ARR_MAX], int file_names_count, Page pages[PAGE_ARR_MAX], int * pages_count) {
assert(*pages_count == 0);
// iterate through files
for (int file_names_idx = 0; file_names_idx < file_names_count;
++file_names_idx) {
FileName file_name = file_names[file_names_idx];
char path[PATH_NAME_MAX] = {0};
sprintf(path, "%s/%s", file_name.dir_name, file_name.file_name);
P(path);
//FILE * f = fopen(path, "r");
// open file
// read file
// output to body
}
}Alright I've got all my paths displaying properly:
path ./series/02_resume.txt path ./series/06_removing-unnecessary-permission-request.txt path ./series/01_hand-sanitizer.txt path ./series/04_digital-security.txt path ./series/old_input.data path ./series/03_ray-reeses path ./series/05_recovering-bitcoin.txt path ./series/whiteness/01_evil.txt path ./series/programming/05_echo-chamber.txt path ./series/programming/06_namespacing-vs-classes.txt path ./series/programming/config.txt path ./series/programming/01_object_oriented.txt path ./series/programming/04_programming-heros.txt path ./series/programming/03_the-letter-i.txt path ./series/programming/02_web-performance.txt path ./series/programming/08_on-exceptions.txt path ./series/programming/07_view-self.txt path ./series/poems/01_fear.txt path ./series/poems/config.txt path ./series/poems/02_mourning.txtA little aside - you maybe wondering what that P() function is all about. Well it's just a little debug function I made for myself last session.
#define P(var) {printf("%s %s\n", #var, var );}
I don't usually do this, but it does make it faster to quickly check the value of any string, which I am do doing on this project a great deal!
I'm taking a slight diversion to set up ctags in vim, which I've never used before.
That was a pleasant diversion
I use CtrlP as a Vim plugin, so this was even more useful
The dangerous thing about diversions is that they can easily sink an entire day. Back to work! I've got to spit out the raw content of each of these files.
Okay that worked for one file, but on the 12th file, I get a segmentation fault.
path ./series/02_resume.txt path ./series/06_removing-unnecessary-permission-request.txt path ./series/01_hand-sanitizer.txt path ./series/04_digital-security.txt path ./series/old_input.data path ./series/03_ray-reeses path ./series/05_recovering-bitcoin.txt path ./series/whiteness/01_evil.txt path ./series/programming/05_echo-chamber.txt path ./series/programming/06_namespacing-vs-classes.txt path ./series/programming/config.txt path ./series/programming/01_object_oriented.txt build.sh: line 4: 6252 Segmentation fault: 11 ./a.outNow this is a bit strange, since I'm doing all my asserts:
FileName file_name = file_names[file_names_idx];
char path[PATH_NAME_MAX] = {0};
sprintf(path, "%s/%s", file_name.dir_name, file_name.file_name);
P(path);
FILE * f = fopen(path, "r");
assert(f);
fseek(f, 0, SEEK_END);
int len = ftell(f);
assert_d(len < PAGE_BODY_MAX, len);
fseek(f, 0, SEEK_SET);
// read file
assert(f);
fread(pages[*pages_count].body, len, 1, f);
*pages_count += 1;
fclose(f);I'm going to to adjust the starting index, to see if it seg faults after 12 files, or if it segfaults when it hits this specific file.
Interesting. When I get 10 files, it doesn't fail, when I get 11, it gives me an abort trap, and when I get 12, it gives me a segmentation fault.
build.sh: line 4: 6401 Abort trap: 6 ./a.outI am not sure what's going on here. I've verified that my files are closing properly. Ah that was silly.
assert_d(*pages_count < PAGE_ARR_MAX, *pages_count);
fread(pages[*pages_count].body, len, 1, f);
I forgot to assert the page count! So I was writing to an array item that didn't exist yet.
These kind of bugs take some time, which is annoying no doubt, but I do feel like the code becomes much better by the end. Particularly when I let these bugs happen, and then add asserts.
Okay, that's all done.
So once again, this has made me realize, it's important to simplify my input output equation. It was a big enough lift to convert filenames into content.
However! There are few bits of meta data I need to get before I proceed. I absolutely need the directory name, and the file name. But beyond that, the parsing can wait.
But I'm also seeing that I don't want to have this be another temporary data structure. Creating a series of disposable data structures, just so that they can be thrown out, seems like a waste of time.
In fact, I'm going to look to see if this should just be one big array of structures.
Yeah, I'm seeing how getallfilesindirs gets the directory and file names, which I'll need for the structure. So we might as well just add them to the main state right then.
I'm talking about combining:
typedef struct {
char dir_name[DIR_NAME_MAX];
char file_name[FILE_NAME_MAX];
} FileName;
typedef struct {
char raw[PAGE_BODY_MAX];
} Page;
That worked great!
So now I'm in this pattern of passing pages and pages_count into various functions.
get_all_dir_names(dirs, &dirs_count);
get_all_files_in_dirs(dirs, dirs_count, pages, &pages_count);
get_all_pages_from_file_names(pages, pages_count);
parse_meta_from_pages(pages, pages_count);
I am wondering if it really makes sense to have these as separate functions. I really do believe that code is easier to understand when you have fewer jumps to make. But right now I am finding it easier to write this, and be able to print the result in between.
I would definitely inline all of these functions if there was a way to reliable eliminate the scope of the dirs variable for instance. Right now the only way is to use a block, but the problem with that is the additional indenting. Hmm.. That might not be a legitimage problem.
I'm going to inline everything I can.
// *******************************************************
// :get_all_pages_from_file_names
// *******************************************************
// Inputs: pages {page->file_name, page->file_name}
// Outputs: pages {page->raw}
{
// iterate through files
char path[PATH_NAME_MAX] = {0};
for (int page_idx= 0;
page_idx < pages_count;
++page_idx)
{
Page * page = &pages[page_idx];
sprintf(path, "%s/%s", page->dir_name, page->file_name);
FILE * f = fopen(path, "r");
assert(f);
fseek(f, 0, SEEK_END);
int len = ftell(f);
assert_d(len < PAGE_RAW_MAX, len);
fseek(f, 0, SEEK_SET);
// read file
assert(f);
fread(page->raw, len, 1, f);
assert(fclose(f) == 0);
// output to body
}
}
// *******************************************************
// end get_all_pages_from_file_names
// *******************************************************
That's better! I think the thing about functions is they provide a pleasant visual beginning and ending to code, but some comment decoration can go a long way.
So why do this? Well now the code matches it's linear nature, it's easy to proceed from one to the other without jumping around, and it's clear which functions are actually used multiple times.
What I don't like, is that then you're accessing these variables from outside of the function, and they feel much more like global variables.
Unfortunately there's no good fix to this. I think I will reference the variables in a more local way though.
A few hours later, and here's what the parse section looks like:
// *******************************************************
// :parse_meta_from_pages
// *******************************************************
// Input: pages {page->raw}
// Output: pages {page->title}
{
for (int page_idx = 0;
page_idx < pages_count;
++page_idx)
{
Page * page = &pages[page_idx];
char *raw = page->raw;
int body_i = 0;
for (int raw_idx = 0, raw_len = strlen(raw);
raw_idx < raw_len; ++raw_idx)
{
if (consume(raw, &raw_idx, "^:title "))
{
for (int title_i = 0; raw[raw_idx] != '\n'; ++raw_idx) {
page->title[title_i] = raw[raw_idx];
increment(title_i, PAGE_TITLE_MAX);
}
}
if (consume(raw, &raw_idx, "^# "))
{
string_cat(page->body, &body_i, "\n<h1>");
for (; raw[raw_idx] != '\n'; ++raw_idx) {
page->body[body_i] = raw[raw_idx];
increment(body_i, PAGE_BODY_MAX);
}
string_cat(page->body, &body_i, "</h1>");
}
else if (consume(raw, &raw_idx, "^`` `"))
{
string_cat(page->body, &body_i, "\n<pre id='pre'>");
for(;!is_match(raw, &raw_idx, "^` ``"); ++raw_idx) {
page->body[body_i] = raw[raw_idx];
increment(body_i, PAGE_BODY_MAX);
}
consume(raw, &raw_idx, "^` ``");
string_cat(page->body, &body_i, "</pre><div class='code-copy'><a href='#' data-action='copy' data-id='pre'>copy</a></div>");
}
else if (raw[raw_idx] == '\n') {
// prevent paragraph tags forming their own paragraphs
}
else {
string_cat(page->body, &body_i, "\n<p>\n");
for(;raw[raw_idx] != '\n'; ++raw_idx) {
page->body[body_i] = raw[raw_idx];
increment(body_i, PAGE_BODY_MAX);
}
string_cat(page->body, &body_i, "\n</p>");
}
}
}
}
// *******************************************************
// end parse_meta_from_pages
// *******************************************************
Day 3 - Parsing
I'm not happy with parsing - it feels like this incredibly hard to debug, and is going to get filled with a bunch of hacks. I think I want to create an additional step here. Like marking where paragraphs start, where links start, where header start, etc. A big challenge is, if I'm checking to see if something is a link, I need to look forward to determine that. Another thing is, it's overwhelming parsing dozens of files. I think I need a test file to test on, and then limit it to that. I also want a structure so that I can review this. Like an abstract syntax tree. Maybe that's a bit much though. The balance here, is how do I create something that is easy to debug, easy to add features to, easy to deeply understand, without creating something extra that's not necessary? I think exporting each step into a series of files would be best. Like this:
/raw/something.txt {filename, dirname, raw}
/raw/programming_something.txt {filename, dirname, raw}
/intermediate1/something.txt {filename, dirname, title, tokens}
/intermediate1/programming_something.txt
/intermediate2/something.txt {filename, dirname, title, html}
/intermediate2/programming_something.txt
Maybe the raw step isn't needed..
I get this feeling when working on this - the fear of creating something that is really fragile, when the slightest thing out of place sends the parser into an infinite loop, crashing everything with no error message.
That's what I'm noticing right now with my asserts - if the thing goes into an infinite loop, an assert will trip, but will give a false positive - saying the body field needs to be bigger, when really it will get filled no matter the size.
I'm realizing how markdown is a language that is made for users, but the programming of it is rather difficult. But this is aligned with the kind of challenges I want to take on.
I think I need to work on this compiler separately, and then plug it back in to this project later. This makes me think that I may have started at the wrong point.
I should probably be trying to get a single stream of tokens, like this.
op(file_start)
op(:directory)
text(somedirectory)
op(:title)
text(sometitle)
op(```)
text(some code here)
whitespace(\n)
text(some more code)
op([)
text(some more code)
op(])
op(()
text(http://google.com)
op())
whitespace(\n)
whitespace(\n)
op(```)
op(file_end)
So let's try that out next. Then the challenge will be to look ahead from "[" operators, to ensure that what I'm seeing is actually an operator and not a legitimate use of the [ character.
Perhaps this ambiguity is what separates markdown style text from normal programs.
https://github.com/markedjs/marked/blob/master/src/Lexer.js
Hmm, maybe the tokenizer has to do more work than I thought.
https://www.markdownguide.org/basic-syntax/
Day 4 - A Simple Compiler
At this point, I could go ahead with the markdown, but I'm realizing that I would benefit greatly by more deeply understanding a simple compiler at this point. The balance is, I don't want this to distract from actually getting a website up, and I know that a compiler is a whole nother topic, that I'll want to blog about later on. But without some basic experience with abstract syntax trees and code generation, I think this will be missing something fundamental. I do want to set an upper limit on this however. I do not want this to be a project that is never completed because of some compiler side tangent. Something deep I've discovered is the importance of starting "root-up". If you imagine your entire program as a tree, like a syntax tree, with the top node representing the entire program, and each branch representing another part of the program, when you get the very bottom, it's all simple implementation. It's good to start down there, because at the bottom, these elements will tell you how to piece them together.Day 5 - Side cases
I tried to use regex for my lexer, but c regex has one big flaw: it's missing \A which detects the very beginning of a string. ^ is not enough, because it will detect every new line. In order to get around this, I did a temporary copy of the code line by line. Working around little quirks like this add complexity to the code. I'm wondering if I should just create me own little regex matcher. I am testing an idea here. I know I can make a simple lexer with a series of strings and specific functions, which is both powerful and flexible. Perhaps this can be done using some simple things. Sidenote, during this corona virus, I really want to make sure I'm able to deliver.Day 6 - Regex
I'm following along with this tutorial But It's in Ruby, and I'm in C, so I had to build own lexer a little more. Other times, I've created an array of structures with the token type, the token value, and then a matching function. This time, I decided to whip up my own regex.Sidenote: Why not go with Posix regex? Well, it's not suitable for a lexer, because it doesn't have any command to match from the very beginning of the file. So you'd have to use ^, and then crop off each line. This would create more complexity and the tradeoff of using regex vs. matching functions would no longer play out.
Here are my tokens:
 Okay, looks like I've got it kind of working. Now to figure out how to make it run a bash script.
Well looks like that's not immediately possible.. but there's a good method for integrating vim with codeclap.
For now though, I'll just add my arguments there..
Okay, looks like I've got it kind of working. Now to figure out how to make it run a bash script.
Well looks like that's not immediately possible.. but there's a good method for integrating vim with codeclap.
For now though, I'll just add my arguments there..
 It's everything I've ever wanted! Now I'll have no problem understanding what's going on. Plus I'll learn so much more about assembly code this way.
Okay that's my time for the day. I didn't get too far into debugging this, but I did discover how to do conditional breakpoints in codeclap.
It's everything I've ever wanted! Now I'll have no problem understanding what's going on. Plus I'll learn so much more about assembly code this way.
Okay that's my time for the day. I didn't get too far into debugging this, but I did discover how to do conditional breakpoints in codeclap.
". Or.. yeah let's just do "". That way, instead of adding padding to paragraphs, I'll just adjust the heights of my nl class. Cool. Ah okay, I see that next up, I need to implement templates, and a way for config data to be read. Oh and I see now that my allocate function should probably be preprocessed, so that the assert there points somewhere useful.
enum TokenType {
def, end,
lparen, rparen,
identifier, number,
whitespace,
TokenTypeEnd
};
char regex_arr [REGEX_ARR_COUNT][REGEX_STR_MAX] = {
"def[:boundary:]", "end[:boundary:]",
"(", ")",
"[:char:]+[:alpha:]*", "[:digit:]+",
"[:whitespace:]"
};
char token_str_arr [REGEX_ARR_COUNT][TOKEN_STR_MAX] = {
"def", "end",
"lparen", "rparen",
"id", "number",
"whitespace"
};
Your eye has to bounce between them to see the types, the regex, and the strings (printed out later in debug). If I wanted to simpify I could remove the tokentypes..
But here's a fun little pattern I've used before:
char regex_arr [REGEX_ARR_COUNT][REGEX_STR_MAX] = {
"def[:boundary:]", "end[:boundary:]",
"(", ")",
"[:char:]+[:alpha:]*", "[:digit:]+",
"[:whitespace:]"
};
#define TOKENS(t) \
t(def) t(end) \
t(lparen) t(rparen) \
t(id) t(number) \
t(whitespace)
#define CREATE_ENUM(name) name,
#define CREATE_STRINGS(name) #name,
enum TokenType {
TOKENS(CREATE_ENUM)
TokenTypeEnd
};
char token_str_arr [REGEX_ARR_COUNT][TOKEN_STR_MAX] = {
TOKENS(CREATE_STRINGS)
};
Now enums + strings are created together.
Now we loop through all the regex and try to get match with capture_match:
for (;code[code_idx] != '\0';) {
int match_found;
for (int regex_idx= 0; regex_idx < TokenTypeEnd; ++regex_idx) {
match_found = capture_match(&code[code_idx], regex_arr[regex_idx], capture_string);
if (match_found) {
...
}
}// tokens
}
Capture match is the meat of the program:
int capture_match(const char * code, const char * regex, char * capture_string) {
int regex_idx = 0;
int code_idx = 0;
for (;;) {
//printf("%c, %c, %s\n", code[code_idx],regex[regex_idx], regex);
if (is_match(®ex[regex_idx], "[:boundary:]")) {
if(!is_boundary(code[code_idx])) {
return 0;
}
inc(regex_idx, strlen("[:boundary:]"), REGEX_STR_MAX);
//code_idx--; // don't include boundary
}
else if (is_match(®ex[regex_idx], "[:char:]+")) {
int alpha_c = 0;
for (;is_char(code[code_idx + alpha_c]);++alpha_c){};
if (alpha_c == 0) return 0; // must match at least one char
//printf("found %d char\n", alpha_c);
inc(code_idx, alpha_c, CODE_STR_MAX);
inc(regex_idx, strlen("[:char:]+"), REGEX_STR_MAX);
}
etc...
}
int i = 0;
for(; i < code_idx; ++i) {
capture_string[i] = code[i];
}
capture_string[i] = '\0';
//printf("match\n");
return 1;
}
Which takes a look at all special circumstances and then checks the match.
23:46
https://www.destroyallsoftware.com/screencasts/catalog/a-compiler-from-scratch
Next up, I'll be create a tree of nodes and printing them all out. I think I'm starting to understand the tree like structure now!
I definitely like the way of moving forward in an array where we reassign the global value.
token = token + 1;
RETROSPECTIVE NOTES 7.3.2020
No surprisingly, this solution where I try to replicate regex comes with mostly downsides and no real upside.
A much better solution comes later!
Day 7
I think I've got all I need to finish up this. I now really understand the relationship between tokens, the abstract syntax tree, and the code generation, just need to bring it all together. Things are working pretty well. Next up, I've got to print out everything as a node rather than as integers or strings.
void parse_arg_names(char * args) {
consume(lparen);
if(peek(id)) {
strcat(args, consume(id)->val);
for (;peek(comma);) {
consume(comma);
strcat(args, consume(id)->val);
}
}
consume(rparen);
}
I've got my nodes printing out with this function:
void print_node(struct Node *node) {
switch(node->type){
case NODE_DEF:
printf("<NODE_DEF name=\"%s\" ", node->def.name);
printf("args=");
print_node(node->def.args);
printf(" ");
printf("body=");
print_node(node->def.args);
printf(" >");
break;
case NODE_ID:
printf("<NODE_ID value=\"%s\">", node->id.value);
break;
default:
printf("print_node node type not found %s",
node_type_arr[node->type]);
}
}
Here's how it looks:
<NODE_DEF name="test" args=<NODE_ID value="x"> body=<NODE_ID value="x"> >Ah actually I see a bug here. When testing with numbers, I realized my body node is just a copy of my args node
def test(1,y) 2 endAh that was just a simple problem with my print_node function.
void print_node(struct Node *node) {
switch(node->type){
case NODE_DEF:
printf("<NODE_DEF name=\"%s\" ", node->def.name);
printf("args=");
print_node(node->def.args);
printf(" ");
printf("body=");
print_node(node->def.body);
printf(" >");
break;
case NODE_ID:
printf("<NODE_ID value=\"%s\">", node->id.value);
break;
default:
printf("print_node node type not found %s",
node_type_arr[node->type]);
}
}
Woo, I got everything working:
def test(x,y) f(1,x,y,z,q) endProduces these tokens:
def(def) id(test) lparen(() id(x) comma(,) id(y) rparen()) id(f) lparen(() integer(1) comma(,) id(x) comma(,) id(y) comma(,) id(z) comma(,) id(q) rparen()) end(end)Which produces this graph:
<NODE_DEF name="test" args=[<NODE_ID value="x">, <NODE_ID value="y">] body=<NODE_CALL name="f" args=[<NODE_INT value=1>, <NODE_VAR_REF value="x">, <NODE_VAR_REF value="y">, <NODE_VAR_REF value="z">, <NODE_VAR_REF value="q">]> >A big challenge here, is I've learned that trying to print from a pointer that doesn't exist will cause a silent failure! No segmentation fault, nothing. The program just stops. So really important to assert on all functions that use pointers as arguments. Never encountered that before! All finished. For fun I generated javascript, c, php, and assembly. (Though the assembly one is particularly fragile) Source Code:
def test(s,y) add(x, y) endGenerated Javascript:
function test(x, y) {
return add(x, y);
}
Generated C:
int test(x, y) {
return add(x, y);
}
Generated php:
function test($x, $y) {
return add($x, $y);
}
Generated asm:
_test: mov %edi, %edi mov %esi, %esi call _add mov %eax, %eax retI think I've learned enough here that I can return to the markdown compiler and finish that off.
Day 8
Well moving over to markdown was a little demoralizing. Changing the input at all immediately caused mysterious crashes. The kind that produce no errors, the worst kind. Seeing that made me want to distract myself. What I don't want to do is fix the problem without building in more error detection. I want to know what is causing these weird glitches and then build in some protection. Okay I've found where this error is happening. In the mystical space between the end of tokenizer function and the next line. I feel like I may need a debugger to actually figure this out. Let's try lldb.. No luck. Ah found the issue! I was assigning to the capture_match string without checking to see if I had gone over. Time to eliminate unguarded assignment to array. Oh wait, I already had that in place, just forgot to use it.
#define inc(var, inc, max) { assert_d(var < max, var); var += inc; }
That was a good reminder. Be extra careful when assigning to an array. Double check that where ever the index is, it's incremented in a careful way!
I could instead write an set function that does the same thing, but this seems a bit more safe and flexible.
C is pushing me to be a better programmer. I want to get to a place where my error detection is so good, I instantly know what the problem is.
Day 9 - Codeclap
Okay back to it. My goal today is to break the compiler and make it really easy to find breakages. I'm going to try using #define to redefine if to dump its process into the debug log. Okay here's a bad bug. If I change the # to a ', I get a horrible error.' testing
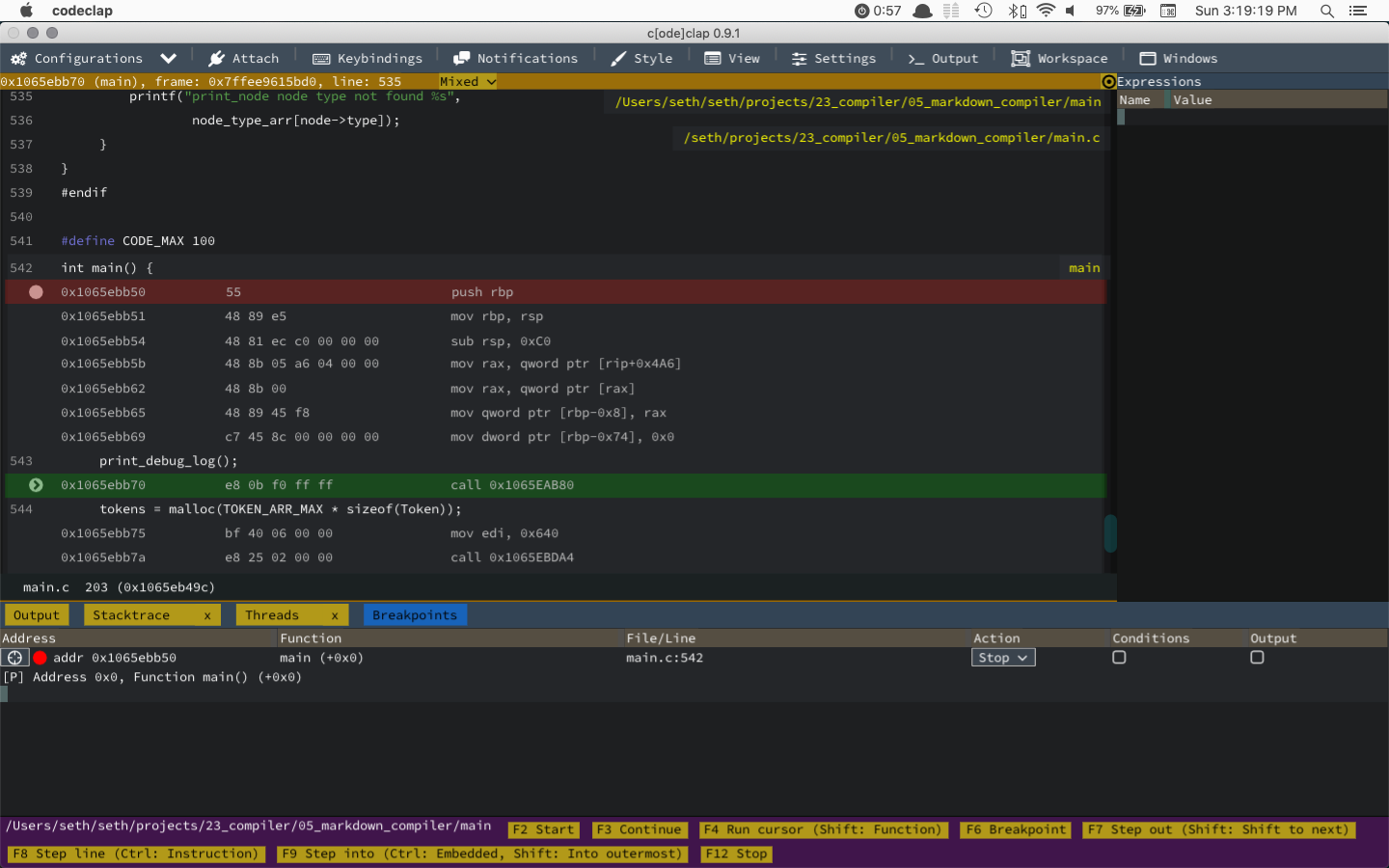
eof() eof() eof() eof() eof() eof() eof() Assert Failed: token_idx < 100, 100This is not cool! Looking at this error, I don't understand anything about where the glitch is happening. I can just see it's adding a bunch of eof tokens, but this issue should be caught long before it gets to eof. I see how this would be nice to step through with a proper debugger. The question is, do I feel like setting up xcode? This feels like an emotional turning point for me. It's like there's a fork in the road. One road leads to testing via adding printf statements and feeling a lot of frustratuion, and maybe eventually leading to the solution. The other way seems to be leading to deeply understanding a core problem of my code. I haven't used debuggers very effectively, usually in my work my code isn't as complex as this, so the benefit of stepping through is usually not so great. Printfs have worked very well. But here, I'm dealing with a fair amount of complexity, and I realize that I'm not understanding the essence of what is going wrong. So Debugger time it is! Ugh. Okay I'm getting this error:
error: unable to spawn process (Exec format error)There's a part of me that just doesn't want to deal with xcode at all. It's time to try out codeclap. This seems like a diversion, but I've been meaning to give codeclap a try, and I think it's a much better learning opportunity to deal with whatever codeclap throws at me. It's $18, but if it works, then that means I don't have to use Xcode or parallels to meet my debugging needs. This feels like a leap of faith, but either way I get to support the handmade community, so here we go!
Okay, looks like I've got it kind of working. Now to figure out how to make it run a bash script.
Well looks like that's not immediately possible.. but there's a good method for integrating vim with codeclap.
For now though, I'll just add my arguments there..
cat program.txt | xargs -0 -I _ ./main _ noneActually. That's not really possible. Okay I'm just going to load in my program from within c instead of passing it in through cat and xargs. Done! That simplifies things. This is so cool!
It's everything I've ever wanted! Now I'll have no problem understanding what's going on. Plus I'll learn so much more about assembly code this way.
Okay that's my time for the day. I didn't get too far into debugging this, but I did discover how to do conditional breakpoints in codeclap.
Day 10 - String issues
Figured out the issue! It was something really fiddly with the length of an array or something. I've also found fiddly issues with having a \0 character at the end of lines.Day 11
This log will now also serve as my deep work log, evaluating how I can make my process better. I have been spending a lot of time on diversions. Let's get this going! I think in doing the tokenizer, I may have discovered that I do not need to do a full compiler. Let's get the tokenizer working for all markdown stuff I may want to use. Then we'll see if I actually need a parser. https://www.markdownguide.org/basic-syntax/ Key lessons so far: Make your test data very simple. Okay time to add more headers, seems easy enough. Done!h1(# heading 1) h2(## heading 2) h3(### heading 3) h4(#### heading 4)Now I'm wondering if my tokenizer shouldn't just skip off those front tokens. That would make my life easier. But I'll save that for later. Looking at the link and image tags, I'm thinking I will need a parser - these tokens should be changed into datatypes, otherwise things will get mighty fiddly. Hmm.. For bold and links, I see those occur inside paragraph tags. I wonder what the best way to handle that is. Should I store paragraph tags as tokens, and then covert the contents to html? Or should I store everything as a token, and then figure out how to parse it out later? I'm going to peek, at this javascript markdown compiler. Okay it's really complicated. I think I'm going to try and just figure this out for myself. My gut is telling me to just tokenizer first, then figure out how things parse together. Got bold and italics working. I think my regex replacement is actually not giving me any benefit. It's basically the same benefit as if I were to have a value and a processing function. However, I'm gong to exercise restraint and not rewrite. Something I'm seeing is that I have two types of functions, some take a single char to do a test, some take a pointer so that they can check more chars. Although in theory I like functions to represent how much data they need, this creates an inconsistancy in calling functions, that feels pointless. I'm not going to do anything about that right now, just noting it. Hmm, just a note for myself, with the current way of doing things, I have no way to make something both bold and italic. This is a warning flag that my tokenizer may be doing too much. Maybe my tokens should literally just grab the "**" and then figure out later if it's going to bold anything or if it's just going to be text. It seems like that might be a good path - because then I can process text in a predictable way. My parser will be able to go through and convert text to bold, links, etc. And each of bold, links, can have text inside them. So I wonder, should my tokenizer create boldstart, boldend tokens? I am currently validating bold_start, but is bold end done correctly? This indicates I should store some state, like boldstarted = true, and then when I look for an end bold token, I only do that if boldstart = true. But this feels like a warning flag. The tokenizer should just convert things to tokens! The parser is in the best position to develop structures.
text1:
type: TEXT
value: "Starting text"
next: bold1
bold1:
type: BOLD
contains: italic
next: text4
italic:
type: EM
contains: text2
next: text3
text2:
type: TEXT
value: "some bold + italic text"
next: NULL
text3:
type: TEXT
value: "some bold text"
next: NULL
text4:
type: TEXT
value: "some ending text"
next NULL
Yeah this is starting to make sense in my mind.
This is what the tree start to look like:
Text "Starting text"
Bold
Italic
Text "some bold + italic text"
Text "some bold text"
Text "someo ending text"
The big realization for me here, is the power of using a linked list, where each node points to the next node, versus having to use an array, which must be known ahead of time.
This is a great use of recursion.
Okay! So now that I've figured this out, I've got some decisions to make.
if(token == ITALIC) {
if(!search_til_eol_for(ITALIC)){
// if no italic on this line then this is text
create_text("_");
}
consume(ITALIC);
parse_next(); // this will recurse down
// When we're done recursing, the next token should be ITALIC
consume(ITALIC);
}
Wow that was a lot easier to write than I thought. This seems sensible.
Currently when I'm parsing through my ITALIC token, I'm dong this:
else if (is_match(®ex[regex_idx], "[:italic:]")) {
int i = 0;
if (!is_italic(&code[code_idx])) return 0;
i += 1;
for (;!is_match(&code[code_idx + i], "_");++i){};
i += 1; // lenght of __
inc(code_idx, i, CODE_STR_MAX);
inc(regex_idx, strlen("[:italic:]"), REGEX_STR_MAX);
}
Which means that anything captured in between my italic symbols, gets captured as plain text, which would need to be parsed out by the parse step.
This is the tokenizer doing too much.
But I'm going to continue on for now, and then drop back to this problem later.
Block quotes have a similar issue - they need to be able to capture all kinds of symbols.
Yeah okay I need to address this now.
I feel like I'm about to have a huge amount of tokens!
What happens if I give all tokens their own types?
I'm going to start out with that.
Something I see right now, is that my capture match is used to increment my code cursor. This means that my captures currently match everything, so an h1 token is (# ). This is probably fine for now actually.
I'm seeing that it may be useful later to split out my tokens into groups, so just having a header token would allow me to consolodate my code later on.
But for now, let's continue ahead.
Okay, I see now that I do want to be able to note whether or not I'm currently on the front line. Actually.. I don't really need that it looks like!
My text file gobbles up everything until it hits an inline token, like a link, or italic or bold. So it will never hit header or blockquote ever!
Hmm.. I see that if we're inside a code block, everything will be text and newlines.
Something like this:
if(token == CODE) {
assert(search_til_eof_for(CODE));
// there must be another CODE in the rest of the file throw error
consume(CODE);
parse_until(CODE); // this will recurse through, converting all tokens to
// text and nls.. Though possibly this could incorporate syntax
// highlighting at some point!
// When we're done recursing, the next token should be CODE
consume(CODE);
}
I'm still learning how to think about the parser - just realized that I my tokens will never have structure, that's the point of the parser. But I'm confident I'll be able to improve this when I get to that point.
oooh. Just realized that I exclaimation marks are what are used to differentiate images from links. So I'll need to change these token names:
#define TOKENS(t) \
t(link_text_start) \
t(link_text_end) \
t(link_href_start) \
t(link_href_end)
char regex_arr [REGEX_ARR_MAX][REGEX_STR_MAX] = {
"[",
"]",
"(",
")",
};
That's better:
t(tag_text_start) \
t(tag_text_end) \
t(tag_src_start) \
t(tag_src_end) \
Actually..
t(obracket) \
t(cbracket) \
t(oparen) \
t(cparen) \o and c stand for open / close.
Wow that hugely simplified my code.
Okay there is just one weird thing I don't understand. If I hit the eof, eof is not detected.. Right now I'm manually checking this in the for loop, and then manually adding the eof token after the for loop.
This one is really hard to debug. I'll have to goto code clap for that.
But not today! Next time.
Feeling great - this tokenizer is almost done for markdown, just going to see if I can figure out this eof exception, and then we can move on to parsing!
Another discovery I've made while working on this project.
Sometimes it's a lot easier for me to write a complex for loop, if I leave off the for loop arguments, like this:
for(;;) {
if(false_condition) return 0;
if(break_condition) break;
++i;
}
This allows me to follow the code more sequentially. I'm going to pay attention to this and see how it affects my ability to return and read code later on..
Oh wow, yeah and this method will make it possible for me to link images.
https://stackoverflow.com/questions/605434/how-would-you-go-about-parsing-markdown
Looking here there's some good converstation - I'm really glad I'm going the parsing route rather than building out html as I go. That seems like a nightmare destined for disaster.
...
Okay I fixed the eof issue using codeclap. I think it was because :text: was checking for multiple characters in a row, even when it already gobbles up it's share.
Day 12 - Parser time!
Finally we've reached the parser. I'm excited to start this, it's where chaos takes structure. A lesson I've learned: When working on something new, simplifiy the program.txt file, so you can deal with a single problem at a time. First I'm going to handle a text token. Alright got a text node working, but it's not very robust. I've got to understand how these nodes link up.. I'm assuming there will be a "next" node.Day 13 - Nested Nodes
So I instantly run into a problem. My current understanding is that nodes look like this:
Text "Starting text"
Bold
Italic
Text "some bold + italic text"
Text "some bold text"
Text "someo ending text"
With the data structure like this:
text1:
type: TEXT
value: "Starting text"
next: bold1
bold1:
type: BOLD
contains: italic
next: text4
italic:
type: EM
contains: text2
next: text3
text2:
type: TEXT
value: "some bold + italic text"
next: NULL
text3:
type: TEXT
value: "some bold text"
next: NULL
text4:
type: TEXT
value: "some ending text"
next NULL
But I don't fully understand how sequential nodes are supposed to stick together.
You know what? Let's not deal with that right now. Let's focus on a single text node.
I see that my model is wrong - these nodes are inside the other nodes, not next.
void parse_text(struct Node * node) {
assert(node);
node->type = NODE_TEXT;
int i = 0;
printf("i found %d\n", i/2);
Token *text_token = consume(text);
node->text.value = allocate(sizeof(void *) * (strlen(text_token->value)));
strcpy(node->text.value, text_token->value);
if (peek(bold)) {
parse_bold(node->inside);
}
}
Got this working!
Next up working on link.
Link:
type: NODE_LINK
text: struct Node *
href: char[200]
This is great. I really see the value of a nice error message system.
Here's what my output looks like when I'm adding the link:
Code: [**_some_**](http://link.com) Tokens: obracket([) bold(**) italic(_) text(some) italic(_) bold(**) cbracket(]) oparen(() text(http://link.com) cparen()) nl() token type not found: cparen main.c:468:5: error: Assert failed: 0 /bin/bash: line 1: 4136 Segmentation fault: 11 ./mainIt's so easy to grasp! Just need to handle cparen in my link. And then when I finish my node implementation, I receive this error:
Node: print_node node type not found NODE_LINKSo now it's time to implement the printing of node_links!
Tokens: obracket([) bold(**) italic(_) text(some) italic(_) bold(**) cbracket(]) oparen(() text(http://link.com) cparen()) nl() Node: <NODE_LINK text=<NODE_BOLD inside=<NODE_ITALIC inside=<NODE_TEXT value="some"> > > href="http://link.com">This code feels like it's getting more robust, this time, there was zero unexpected errors, no segfaults, nothin. I'm noticing that using the heap is rather enjoyable - I don't have to worry about making a decision of the size of the stack beforehand. Although I know that I'm using temporary memory for printing out nodes. That's the weak point, it'll cause a segfault easily. I guess I want to override strcat so I can avoid that issue. There we go:
void string_cat(char * t, char * str, int max){
int needed = strlen(str) + strlen(t);
assert_d(needed < max, needed);
strcat(t, str);
}
It's actually pretty easy to track down potential problems. It's usually with arrays:
strcat
strcopy
sprintf
What's cool about using the heap, is that I can set a memory budget, and easily see how close I am to hitting it. Where as with fixed arrays, I only receive info if I've already hit the end.
Hmm.. Yeah I guess that's because when I'm working with heap I can allocate on the fly. And so long as I'm doing this in an intelligent way, it's not like a malloc everytime.
This only works well for individual variables though. I can't use it for strcat, because strcat doesn't know what size to allocate for.. the next strcat could use even more memory.
Okay! Next up. How to do the "next" item.
First I setup my markdown.txt in a very simple way:
hello there"there" just overwrites the "hello" value in the text node.
<NODE_TEXT value="there">Time to add next to my node.
void parse_text(struct Node * node) {
...
node->text.next = allocate(sizeof (struct Node));
}
Then I've got to add "next" to my text Node structure.
struct Node{
NodeType type;
union {
struct { // NODE_TEXT
char *value;
struct Node * inside;
} text;
Then my brain has to spin for a few seconds, because recursion.
parse_any(node->text.next);
but that does nothing, probably because it hits the newline.
A quick jump to codeclap confirms that!
So thinking about this some more, I should be looking to see if a new line exists next, if it doesn't, then we're probably at the end of the function right?
I'm not exactly sure..
Hmm.. getting this error:
Tokens: text(hello) nl() text(there) nl() parse any: token type not found: eofNow that I'm getting comfortable with codeclap, it's no problem to jump in to the code and really understand where it's getting messed up. But before I do that, I'm going to see if this error is showing up with a single line of markdown. Indeed, my hunch was right. I can see from this that a new line token is being created even when there is no newline! This is not good, and it's really challenging to debug with codeclap because it involves iterating through a lot of loops and if statements, a slow and painful process. I'm going to mess around in code clap some more.. I want to avoid speeding through this problem. Oh wow. I think I just discovered that files always end with a new line. Okay cool. So I've edited my tokenizer to accept a newline and an eof token at the end. And it works!
Tokens: text(hello) nl() text(there) Node: <NODE_TEXT value="hello"> <NODE_TEXT value="there">Hmm! I just reinforced something. I often use pointers as aliases, but that's no good if the thing hasn't been assigned memory yet! I'm wondering if I should make "next" a common thing, since everysingle node will have a next.. I redid my node printing to be easy to read, cause that's something you can do when you control absolutely everything.. and we can see this is working really well!
Tokens:
obracket([) bold(**) italic(_) text(hello) italic(_) bold(**) cbracket(]) oparen(() text(http://mycoolwebsite.com?fdsafd=fskdjf&fdskjfd#3434) cparen()) text( testing) nl()
nl()
bold(**) text(there) bold(**)
Node:
LINK href="http://mycoolwebsite.com?fdsafd=fskdjf&fdskjfd#3434"
BOLD
ITALIC
TEXT value="hello"
TEXT value=" testing"
NL
NL
BOLD
TEXT value="there"
I've found a really challenging problem!
bad**news**In this case, the "bad" text node, should have the bold node as it's next node. But if I allow that, then the "news" text node will also consume the next bold token as part of it's next node! We'd just just zoom in and in and in, and we'd never escape. Node-ception. It seems to me that I'm learning a potential property of tokens - they must communicate whether they are a beginning or an ending. If they do not differentiate that, then node-ception happens. I'm having an unsettling feeling in my stomach - like I may need to go back to the tokenizer and fix a lot. Hmmm.. I'm going to slow it down right now. Maybe I'm incorrect about this.. I could just check to see if the prior token was a bold.. Research time! After lunch. Something tells me I'm going to have to try this out myself. It's really hard to comprehend other parsers. I guess I could just have a simple global flag - where strong is either true or false. If it's true, then parse_any will return null if the next type is a bold. That worked amazingly well! I need to take a break. But really pleased with how this parser is coming. Next step will be working on the code node, and I'm also aware that paragraphs are an issue I'm avoiding..
Day 14 - Code Token Issues
So here's an issue that I've been avoiding! My tokenizer is very aggressive, and converts all symbols to tokens whether or not they're in the right context. So in other words, tokens are created, whether or not they are correct. While this made the tokenizer very simple, it does add complexity to the parser. The only question is, is the parser in a better position to judge the validity of the tokens, than the tokenizer is. Probably! But there's only one way to find out. Let's take a simple problem and try out a solution. Problem 1: So in other words, inside the "```" symbols, those symbols are all stored as tokens, and they will need to be converted. Hmm.. Okay something that I'm realizing when thinking about what the right solution is here.. A big reason I like a Data Oriented process, is it converts everything to inputs and outputs. However, for this to be a benefit, the inputs and outputs have to be correct! In this case, I'm talking about having the tokenizer spit out incorrect data, but then detecting it inside of the parser. So that would seem to be a vote to have the tokenizer check to see if there is a valid link, before tokenizing the link tokens. However, I wonder if that is abusing the tokenizer. Like at that point, I might as well send a link token, that contains two values: the href and the inner text value. Is it alright for a tokenizer to contain multiple values? I think for links it's okay if I just return a token that looks like:link([my text](http://someurl.com))Hmmm, but then "my text" could have a token in it that gets ignored, like bold or something. This is challenging! Something I want to entertain: Perhaps it is not a good idea for my to separate tokenizing and parsing for a markdown compiler. A markdown compiler is inherantly different from other programming languages. The tokenizer can never know for sure if something is a string literal, or something that should be converted into a token. Not without doing a lot of work first - and if you're going to do the work, you might as well create the node right? Hmmm.. As I look a this problem more, that might not be so. Creating nodes is a bit complex, and it would be nice to have correct tokens before hand. So can I just make my tokens accurate? So before capturing a link token we'd check to see if it was a valid link token first. And then we'd set a state switch in the tokenizer to indicate we're in link mode. Or in bold mode, or in italic mode. This definitely adds complexity to the tokenizer, but my brain can't even begin to figure out how to create nodes without having tokens before hand. Okay, well! This is definitely going to break my regex-like code. It's starting to seem like that is a very rigid solution. Makes sense - it's more generic. Okay, problem 1: Italic or Literal?
Code: before _ after Tokens: text(before ) italic(_) text( after) Expected: italic Actual: eofFirst up, we want this italic to be brought into the text field.
if (is_italic_char(code[code_idx + i])) break;
Looks like we just need to update this function to properly see if it's an italic. Before I do that though, let's see where else this function is used.
Ha. That's it. That's the one place. Well first off we've got to make it work for pointers instead of chars.
if (is_italic_char(&code[code_idx + i])) break;
...
int is_italic_char(const char * c) {
if(c[0] == '_') return 1;
return 0;
}Boom.
int is_italic_char(const char * c) {
int i = 0;
if(c[i] != '_') return 0;
++i;
for(;;++i) {
if (c[i] == '_') break;
}
if (i > 1) return 1; // must include at least one char
return 0;
}This code is clearly wrong, but it works anyways. Why is that? Well looking at code clap, it's clear that it reads past the end of the string to infinity. Evenutally it finds another '_' in memory and finishes up, making it a valid italic char.
for(;;++i) {
if (is_eol(c[i])) return 0;
if (c[i] == '_') break;
}Add is end of line to my fail condition fixes this.
And now we're on to phase two of the problem. Matching the ending italic char.
Of course the end italic char will never match currently, because it's okay for an ending char to not have an italic char following it.
So for this we need some state.
Now I want my tokenizer and parser to have completely different state so we don't get any nasty issues, so it's time to create a struct.
And here we are!
struct TokenizerState {
int italic_opened;
};
struct TokenizerState tokenizer_state = {0};
int is_italic_char(const char * c) {
int i = 0;
if(c[i] != '_') return 0;
if (tokenizer_state.italic_opened) {
tokenizer_state.italic_opened = 0;
return 1;
}
++i;
for(;;++i) {
if (is_eol(c[i])) return 0;
if (c[i] == '_') break;
}
if (i > 1) {
tokenizer_state.italic_opened = 1;
return 1; // must include at least one char
}
return 0;
}Oops that didn't work. I need to completely rework my italic code!
else if (is_match(®ex[regex_idx], "[:italic:]")){
if(code[code_idx] != '_') return 0;
tokenizer_state.italic_opened = !tokenizer_state.italic_opened;
inc(code_idx, 1, CODE_FILE_MAX);
break;
}
This regex code style matching is starting to feel like a completely pointless thing. I'm about ready to tear it all to pieces.
Code:
start _italic text_ regular text containing _underscore
Tokens:
text(start ) italic(_) text(italic text) italic(_) text( regular text containing _underscore)
Node:
TEXT value="start "
ITALIC
TEXT value="italic text"
TEXT value=" regular text containing _underscore"
And that works great!
So basically, for any of these inline character, my tokenizer must take a complexity hit.
I think I'm also refining my use of functions a bit. Right now I've got functions called "isitalicchar", which probably deserves to be inlined, and have some of it's guts converted into functions. Or maybe not.. I kinda like that I only need to consider inputs and outputs within this function.
Day 15 - Tokenizer
Okay! We're moving to a mode where the tokenizer can have a little bit of state to note when a bold or italic has opened, and it will use obold cbold (open bold, close bold) rather than a generic bold token that could mean either. This means the parser does not have to do more work than it needs to. Okay this is coming along, I've got it working for links. However I really see how this regex function is awful, because it couples my token values with my movement through the string. Like, right now I HAVE to return link(](mylink here)) That's a lot of junk. Maybe instead of a regex struct, I should just make a simple case statement.
Inputs:
code
Outputs:
string to capture in token value
num to increment code_idx
Like I gravitate to solving this problem with a struct:
{
{ eof, "[:eof:]" }
{h5, "###### " }
{quote, "> " }
{code, "[:code:]" },
{config, "[:config:]" },
{text, "[:text:]" },
{obold, "[:obold:]" },
{cbold, "[:cbold:]" },
...
}
But that is kinda silly. Like I'm basically doing this pattern, but with more complexity:
{
{ eof, "", "eof" }
{h5, "######", "normal" }
{quote, "> ", "normal" }
{code, "", "code" },
{config, "", "config" },
{text, "", "text" },
{obold, "" "obold" },
{cbold, "", "cbold" },
...
}
Where the third argument is the matching function. Which is how I used to do my tokenizer..
Both of these methods are unsatisfactory because they either overload the "value", or they provide a useless value when using a matching function like obold.
I think what I actually want is something where the iteration happens right in a switch statement:
for(int i = 0; i < TOKEN_ENUM_MAX; ++i) {
switch(i) {
case eof: return eof();
case h5: return normal("#####");
case quote: return normal("> ");
case config: return config();
case text: return text();
case obold: return obold();
case cbold: return cbold();
}
}This gives me the ability to specify functions with an arbitrary and differing number of functions, while having the benefits of being able to edit it all in one place.
I think this will give me the optimal amount of code reuse, because neither version before this can take an arbirary amount of arguments.
But I won't do this just yet. I'm just noticing how pointless this regex emulation is. I'm going to wait to feel more of the pain of it.
Okay I see some weird glitches around bold and italic nesting. Not sure if it's serious enough that I'll address it though.
Code: _**_example** Tokens: oitalic(_) obold(**) citalic(_) text(example) cbold(**) nl() Expected: cbold Actual: citalicI guess that actually is a pretty good error message! It's expecting a bold closing tag, but instead it encounters a closing italic. Makes perfect sense. I'm going to say that's actually a desired result. What else is markdown going to do? Assume that these are both just plain text underscores? That doesn't seem to make a good deal of sense. Okay, so links, images, bold, italic, code is working. Now I just need to do some deeper testing, and we should be done with the parser! Then we'll move on to code generation, which will be easy. Okay a quick test and it seems to be parsing really well! However, it's not dealing with a 2038 line file (this markdown file) very well. It's seg faulting on the parser. I'm not that worried though. This project is giving me some confidence in being able to solve hard problems. Especially now that I've got codeclap working, I'll be able to find exactly where it kicks the bucket.
Day 16 - Seg Fault
Well that crashed code clap.. Dang.. This is actually really difficult. It's not running out of memory.. I think I want to just do some code generation right now. Wow this is so easy!
void generate_html(struct Node * node) {
assert(node);
switch(node->type){
...
case NODE_TEXT:
printf("%s", node->text.value);
break;
case NODE_BOLD:
printf("<b>");
generate_html(node->bold.inside);
printf("</b>");
break;
case NODE_ITALIC:
printf("<i>");
generate_html(node->bold.inside);
printf("</i>");
break;
...
}
if (node->next != NULL) {
generate_html(node->next);
}
}
K, one thing I've uncovered is that NODE_UNDEFINED is happening right after the text field.
Ah I see why that was. Because I was allocating a next node even if there was no next node, which can happen after you've gone inside a node, and need to pop back out.
int is_deadend(int type) {
switch(type) {
case href: return 1;
case citalic: return 1;
case cbold: return 1;
default: return 0;
}
}
Now I can just check is_deadend before allocating.
There we go.. All good.
A lesson here - I remember when I ignored this problem of undefined nodes early on. Now at the time, I probably had no way of fixing it, because I hadn't estabilished the idea of obold + cbold, so there was no easy way of telling if I was at the end of an inner path. So it was the right thing todo, to skip it, BUT I should have definitely put a note in the code to fix this later on.
Also another lesson, one that I have to keep learning, is that you can NOT allocate something inside a function, and have that allocation carry up through the pointer. Because the allocation is defining the pointer! This is something my brain doesn't want to absorb - my mental model of pointers is that they are these magical floaty things that you can alter anywhere you want. But the reality is, until they are allocated, they point to the wrong place. There is no point and sending an unallocated pointer anywhere.
So this is looking pretty good:
-------Code-------
**_test_**
[test](this)
------Tokens------
obold(**) oitalic(_) text(test) citalic(_) cbold(**) nl()
otagtext([) text(test) href(](this))
------Nodes-------
BOLD
ITALIC
TEXT "test"
NL
LINK href="](this)"
TEXT "test"
------Html--------
<b><i>test</i></b>
<a href="](this)">test</a>
Next up will be factoring my tokenizer a bit - it shouldn't have any of the symbols inside it's value.
Using a switch statement as a data structure
That means, goodbye generic "regex" function. I'm going to enjoy this one! The tokenizer is something I've spent the most time with, and I've reworked a number of times on projects before this, but this time I feel like I have enough knowledge to create it in a way that's flexible and simple.. Here's what I'm thinking:
void match(token_type_idx) {
switch(token_type_idx) {
case h6: return normal("###### ");
case h5: return normal("##### ");
case h4: return normal("#### ");
case h3: return normal("### ");
case h2: return normal("## ");
case h1: return normal("# ");
case quote: return normal("> ");
case tk_code: return token_code();
case text: return token_text();
case obold: return token_state("**", bold, 1);
case cbold: return token_state("**", bold, 0);
case oitalic: return token_state("_", italic, 1);
case citalic: return token_state("_", italic, 0);
case otagimage: return token_state("![", tag_text, 1);
case otagtext: return token_state("[", tag_text, 1);
case href: return token_href();
case ctaghref: return token_state(")", tag_href, 0);
case eof: return token_eof();
default: assert(0);
}
}
It looks like a data structure, but it allows me more flexiblity and code reuse.
I'm going to start by leaning on global state, so I don't have to pass variables up and down, and I want to notice what issues come up from doing that. Like I imagine on some level it will make the code less traceable, but I think there's an opportunity to use global state here in a way that things are actually simpler.
We'll see.. I may just need to create an object that I pass all the way down and up.
Yes this is really paying off!
I'm finding new ways to compress my code down.
I particularly love that the fairly complex functions which involve managing state, can now be collapsed:
case otagimage: return token_otagimage();into this:
case otagimage: return token_state(tk, tag_text_opened, "![");
Next up, I can change up headers. No need to store them all as separate tokens. They can be a single token, that stores a number in it's value.
Done.
int token_header() {
int token_type = header;
char * cursor = &input[input_idx];
int i = 0;
for(;cursor[i] == '#';++i);
if (i == 0) return 0;
if (i > 6) return 0;
if (cursor[i] != ' ') return 0;
create_token(token_type, cursor, 0, i);
++i;
inc(input_idx, i, INPUT_MAX);
return 1;
}
I've noticed myself developing this style, where I use very simple if statements and return a 1 or 0. It seems to make it very easy to scan. I think this is a problem in programming languages - if statements with multiple conditions quickly become way too hard to read, this makes jumping out to a function have a benefit it normally wouldn't have.
RETROSPECTIVE NOTES 7.3.2020
This switch-as-a-data-structure approach is one of my favorite things to come out of this project!
Day 17 - Global State
First step, let's make a Global struct that contains all the global state. Done.. Okay this is pretty clear now.
struct Global {
Token * tokens;
int token_idx;
void * memory;
int memory_allocated;
int memory_idx;
char * input;
int input_idx;
};
This seems pretty reasonable. We've got essentially 3 things that are global:
input, tokens, and memory.
Something I'm aware of, is I've added a bunch of things which increment things without protection, I may need to go back and replace all those with my inc function to be safe.
Something I've learned, for blocks of code or functions that can potentially be reused, it's useful to put the changing data at the top, so you don't have multiple places you need to customize. And then it's easy to see when it's ready graduate it to a reused function.
I will say it really is demoralizing to see this:
tokenizer();A function that takes no arguments and returns no arguments makes me afraid. I may as well not have this as a function. I'm realizing my emotions are really helpful here for evaluating my progress. They tell me what I've learned over decades about programming. Cognitively, I may be satisfied with the code, but my belly tells me I would be very unhappy returning to this code trying to fix something or add a feature. I'm using functions to cleanup switch statements, which is not ideal! This is feeling like the first downside I've experienced of C.
Day 18 - Compiler Complete
Woo! I put this article in, and no more segmentation fault! I think that was because it wasn't set up to process config files yet. Regarding state, I've removed "tokenizer()" and now I just have a simple for loop. I just realized quotes was not active, but a few minutes later, with just a few lines of codes, it's in, with full nesting of bold and italic fields built in. This is the first time I've really experienced the benefits of recursion, and it's a real strength of this node-based compiling. I think we're done here! It's time to go one level up, and see what the next problem is.Day 19 - Linking
Next up, the question is, how shall I use this new markdown compiler? Right now, it just spits a bunch of text out through printf. That was great when it was just processing a single file, but now I need to: 1. Iterate Through Files 2. Tokenize All 3. Parse All 4. Generate HTML for all. This means saving these printed things to files rather than printing them. /output/filename_tokens.txt /output/filename_nodes.txt /output/filename_html.txt Hmm, this strikes me that I really should start seeing this program as input -> output. It takes the input of a single filename, and it generates these 3 files. But maybe I should also consider that there are multiple files at play here. I can't handle memory the way I've been doing it.. Or, maybe... What if I just call out to command line for each specific file? It's kind of silly, but that would keep everything completely separate. Otherwise, I'd need to what.. Navigate through all the structs and free all the memory I've allocated? Hmm.. It does occur to me that I've been storing my nodes as pointers, and I'm not 100% sure I actually need to do that. I was doing it because.. I don't even remember now.. Oh, probably because it is recursive. If a struct contains its self, then it would be infinitely large! Yeah lets just make this compiler a bit more robust - it won't printf anything. Stuff will just written to files. Done! Now we output:/debug/<articlename>_tokens.txt /debug/<articlename>_nodes.txt /output/<articlename>.htmlSomething that just came back to mind - I'll need to make a decision about how I handle new lines in my compiler.. Likely I want to handle this in the tokenizer. A text line should not break unless it's followed by a newline character and a non char character. Or.. I could handle this differently. Like, it's actually really annoying that everything is in a paragraph. A paragraph ends up just being a hassle. Yeah for now, I'll just make newline characters be "
". Or.. yeah let's just do "". That way, instead of adding padding to paragraphs, I'll just adjust the heights of my nl class. Cool. Ah okay, I see that next up, I need to implement templates, and a way for config data to be read. Oh and I see now that my allocate function should probably be preprocessed, so that the assert there points somewhere useful.
Day 20 - Start with the inside first
Alright, one revelation that's come from this project is I'm not gonna do too many low level projects like this a year! Or the next one I do has got to yield a bigger output. I mean it's been 20 days, and I'm just trying to put together a website. Something I also realized, is that because I'm only using malloc once, my memory management is super simple! I don't need to navigate the structs and free up the memory, because it's all just pointing to one memory block. Literally all I have to do is set my memory index to zero. This is really showing the benefit of the handmade method. Nice. Now we have no malloc inside of my compiler. And calling it is as simple as:
int memory_allocated = 13400000;
void * memory = malloc(memory_allocated);
markdown_compiler(memory, memory_allocated, "markdown.txt", "test");
Alright! So now we can easily convert all markdown to html. So what's missing?
Well, for each html file, I need to generate a menu to all the other menu.
Which means that I can't just generate things right now.. Or if I generate it now, I'll need to load it later.
I am finding that having this blog is really useful for looking into the future - sometimes it's tempting to just start coding, but articulating the problem is good to slow things down.
So I need to get a config struct. This struct will contain:
struct Link {
char name[];
char src[];
}
struct {
char topic[];
char filename[];
char title[];
char preview_text[];
char preview_image[];
Link menu_links[];
int menu_idx;
}
Ah so it occurs to me, we need the titles of each of these linked files.
So markdown_compiler will not output the final file, but another intermediary file.
We'll need an extra step to apply the template and the menu.
My original intent was to migrate markdown_compiler.c into the program that scans directories, but I think I'll actually work backwards instead.
That's a lesson I've repeatedly learned. Start with the inside first.
Hmm, just realized this struct won't work. I need to have this:
char dirs[DIRS_MAX][] = {
"programming",
"health",
"whiteness",
};
int dir_idx[DIRS_MAX] = {0};
char article[DIRS_MAX][ARTICLES_MAX][ARTICLE_NAME_MAX] = {0}
Day 21
So we will send in an array of articles, for this specific directory (topic?). I need to develop some language around what I'm doing here. Topics, Categories, group.. I like group, because a group can never be an article. And for the file with the text in it? Article, entry, item, piece.. Yeah article makes sense. So we have groups of articles!
char groups[GROUPS_MAX][] = {
"programming",
"health",
"whiteness",
};
int group_idx[GROUPS_MAX] = {0};
char article[GROUPS_MAX][ARTICLES_MAX][ARTICLE_NAME_MAX] = {0}
My inside-first method works well, and indicates what I need to work on next. In this case, I need to know move up and import a file from an arbitraty directory, so I'll use some of that directory scanning code in my compiler.
Day 22
Damn, I'm realizing how complex this problem is. I am parsing to html, then reading it back to generate the final thing. That's good I guess. It's a meaty problem that I'll have to stretch myself to resolve. Okay so first let's simulate a file that has no series. Ah I have to create directories otherwise this fails, fine. That worked, now I'm going to take the output, and export it to a simple html template. Okay, now that I'm putting more logic in the main file, I want to have some encapsulation. To my knowledge, with C, there's 2 ways to do that. 1. Rename variables to have a prefix. 2. Dynamically load the library.Day 23
I'm at the phase where I just want this to be done! It's May already. Okay I just learned about how to properly encapsulate this stuff! Instead of "#include", I should just link the two files together:gcc markdown_compiler.c main.cAnd then use "static" on any global variable I have in markdown_compiler that I don't want to be exposed in main.c. And I just found out that defines are not used in other files when linked this way - great! And now I finally grasp why header files are used, and yet, I'm not convinced I need them. I'll just use:
extern void markdown_compiler();for the function right now. I imagine for the data structure, things will be different. This seems really silly, but wow what a great revelation. It's weird though.. I know that C has always wanted me to use header files, but I just found them to not be needed. By not following the standard way of doing it, I have a much better understanding of why one would use them, and what the tradeoffs are. Ah it just occurred to me, by putting these config variables inside of the html files, I am forcing myself to do two passes. One to read the config variables, and one to export the file. However! If I store the config elsewhere, then I no longer need to do that. Maybe I should have one single config file which structures everything?
:group programming :group_title Programming :tags programming,coding :nav on :link 01_object_oriented "Object Oriented" :template normal :link 02_web-performance "Web Performance" :link 03_the-letter-i "The Letter I" :template minimal :link 04_programming-heros Some article not published yetYeah I dig this. We'll do one pass to see if nav is on, if it is, then we'll extract all the links, and convert them to an html nav. Whoa. I just realized that this actually makes it so I no longer have to do a sweep through my directories. I'll just read the config file and derive everything from there. Yet another benefit of "starting from the inside"! All the upfront work I did to learn how to iterate through the directories and files is no longer useful. Then to make this as flexible as possible, I'll hand over the template, and a series of replacement strings, along with which position the body should be in. Hmmm... but what about when I want to inject other stuff into the template, like styling + scripts.. Perhaps this should be hardcoded a bit.. I'm also thinking, there's no reason I can't just get the title from within the file, since now the template will be there.. Hmm. Okay yeah I still need to do a scan of each of these groups, so some of the code I initially did will still be used here. Ah.. Yeah I see.. Okay no need to do title inside an article, since I already need to know the title, in order to generate the nav. I'm finding that the benefits of doing things automatically are outweighed by the complexity.. Like sure it's convenient to not have to type out the full filename, but I think I'd rather just get an error message if I get it wrong. Next time - exporting the full html for each file.
Day 24
So my strategy for getting this done has been to get up early and spend the first couple of hours every day on it. I'm wondering if it would be better to do some weekend sessions, where I get into a deep work flow. This week I've found that I can actually get good work done starting in the afternoon, and put in 8 hours, so this might be a new work style for me. Alright, next step, I'm going to fake the creation of one file, and then two. Let's start with a template inside of the markdown file, and then I'll change it up. This is using the "start inside" method - rather than worrying about passing in the template, I'm going to bake the template inside, and then setup the passing in part later. Alright that worked great, here's a simple template:sprintf(temp, "<html><head>\n<title>%s</title><style>%s</style></head><body><div>","title", "style here"); generate_html(temp, &node); sprintf(temp, "%s</div><script>%s</script></body></html>", temp, "script");Learned something about sprintf, I can't use sprintf to insert something before temp, while using temp, if that makes any sense. This does have the undesirable property of requiring my templates to have a header and a footer, but I think that's alright, since there won't be many of them.. Although it will make it more confusing when specifying, because I'll be autogenerating the "header" and "footer" part.. Like when I pass in template, it would be great to just be like, the template is "single.chtml" instead of "single" and then auto generate the rest. It's a small thing, but the first way is immediately understandable, where as the latter requires some auto generation and string concatination. I'm realizing now, that I'm not sure why I'm using this temporary string pattern for generating html.. Why not just use regular memory? I see.. I've made a lot of functions for manipulating temp.. but why? This really isn't a good use of the model of "temporary" memory. Because this memory needs to persist till the end of the function, not as some kind of one off thing. Ah I see, I'm using temp memory to just drop text into a file.. Meh, okay not a big deal. But I see I'm setting myself up to possibly triggering a segfault with these sprintfs..
char footer[] = "%s</div><script>%s</script></body></html>";
char script[] = "script goes here";
assert((strlen(temp) + strlen(footer) + strlen(script)) < TEMP_MAX);
sprintf(temp, footer, temp, script);
There that fixes it. Not fun though! I really want to build my own sprintf, so I don't have to think about this stuff once I solve it once. That would be a nice goal, to make it so you basically don't need any asserts hanging out in the code. But that's for another day!
Damn, reading these templates from files and loading them into strings is annoying. It means I have to set up new memory for this, which adds friction. And of course I have to do it twice, once for the header and once for the footer. Not cool.
I'm wondering if I should just pass in these headers and footers into markdown_parser before working on this..
Well there's one other idea I want to vet. I see how I am constrained by memory here, and the desire to not want to create more complexity.
I could iterate through a file, that has a series of keywords, that when I hit them, I would switch over and add the title or what not..
That seems a bit more complex than I need.
It's probably better to just manage memory for these headers and footers on main.c. Yeah let's just pass it in.. it's getting too complicated in here.
char header[] = "<html><head>\n<title>%s</title><style>%s</style></head><body><div>";
char footer[] = "%s</div><script>%s</script></body></html>";
char title[] = "title goes here";
markdown_compiler(memory, memory_allocated, "_single", "markdown.txt", "test", header, footer, title);
Okay and now I'm loading header and footer from their files:
{
char filename[] = "templates/single_header.chtml";
int max = HEADER_MAX;
char * buffer = header;
FILE *f = fopen(filename, "r");
assert(f);
fseek(f, 0, SEEK_END);
int len = ftell(f);
assert(len < max);
fseek(f, 0, SEEK_SET);
fread(buffer, len, 1, f);
}
This is a convention I often follow when I'm creating bits of code that I can imagine being functions at some point. Putting the arguments at the top makes it obvious what the function arguments are.
I'm also getting into the convention of adding a comment that says:
// @dangerWhenever there is a segfaultable situation - probably better to fix those earlier rather than later! This definitely adds friction to my coding, but I know better to think that the solution to this problem is moving to a garbage collected language or something. I just want less friction, not less control and understanding. Really excited for JAI for this reason. It's probably a good idea to run through old Jai videos and make sure I understand the concepts, and the things I need to do in C in order to run up against the problems that Jai solves.
read_file("templates/single_header.chtml", header, HEADER_MAX);
read_file("templates/single_footer.chtml", footer, FOOTER_MAX);
Alright, I've got my header and footer reading code in, and everything seems working pretty well!
Let's read a second file.
/bin/bash: line 1: 40367 Abort trap: 6 ./mainyikes. Not pretty! So I'm going to experiement to see where the error could be occuring here. It's not happening on export. It's happening on import of markdown2.txt And it doesn't happen if I switch the order and import markdown2.txt first.. very strange! And it doesn't happen if I read in markdown.txt twice.. Time to jump into Codeclap! Okay it passes by the tokenizer fine. It hits the trap somewhere in the parser! Alright let's dig down another layer. Hmm I think it fails in parse_rules.. in parse_text? This is kind of an annoying debugging process! But I'm sure by the end of it I'll have learned something very valuable that I won't forget! Ohhhhhh... It looks like all my nodes from the prior markdown compile session are still there! Very bad. It's probably trying to add to the bottom of those or something. Okay I think it failed on parse_text, and the first strcpy.. Verifying. A few other concerning things, I see token_idx is 8, which seems like more? But maybe that's right.. ooooh I see an issue! When we allocate memory, it's not empty, which is fine, but perhaps we should at least set the character to \0 Hmm... I guess that's actually not much of a problem.. Weird, I'm actually not sure what this strcpy abort is about. It seems like even with the issues I'm seeing regarding memory, it should still be able to copy the memory over.. Unless text tokens have such small space and I haven't properly done an assert on strcpy.. Ah I see I can't have allocate clear anything because it sends back void memory. I wonder if I can set an void * to NULL or something.. Ahha, tokens has been set wrong. I see.. I'm not writing in the \0 character, so it's left open.
void create_token(int type, char * cursor, int len) {
//printf("creating token %d, %s %d\n", g.token_idx, token_type_arr[type], len);
Token * token = &g.tokens[g.token_idx];
token->type = type;
assert(len < CAPTURE_STR_MAX);
token->value = allocate(len + 1);
for(int i = 0; i < len; ++i) {
token->value[i] = cursor[i];
}
inc(g.token_idx, 1, TOKEN_ARR_MAX);
}
This fixes it:
void create_token(int type, char * cursor, int len) {
//printf("creating token %d, %s %d\n", g.token_idx, token_type_arr[type], len);
Token * token = &g.tokens[g.token_idx];
token->type = type;
assert(len < CAPTURE_STR_MAX);
token->value = allocate(len + 1);
int i;
for(i = 0; i < len; ++i) {
token->value[i] = cursor[i];
}
token->value[i] = '\0';
inc(g.token_idx, 1, TOKEN_ARR_MAX);
}
I got to say, that doesn't feel too good.. Is this really the solution or just a hack?
maybe len should always include the \0?
It is rather scary that text from one file can bleed over to the next file.. Maybe I should clear out the memory entirely inbetween..
This is requiring me to be more rigorous with my code though.
Ah I see, this is the right way to do it. Always create a \0 because the source string might not have it.
I just wish there was a way to force this issue to come up sooner.. Maybe by writing over empty memory with full memory so I can't rely on \0?
Day 25 - Segfault
Since I've started this, the global movement to end police violence has begun, and my silly little project about creating a markdown compiler in c so I can have a blog seems vanishingly important! I have so many ideas that are starting to feel way more important. And yet I'm so close! It would be a shame to not see this through to the end. Let's write over memory and see if I come across an issue. Indeed, if I write over all memory, I get another segmentation fault!
char * memory = malloc(memory_allocated);
for (int i = 0; i < memory_allocated;++i) {
memory[i] = 'x';
}
This is kind of annoying going step by step through with codeclap..
Yeah this is impossible.. the error is happening somewhere in a recursive function I think, meaning I'd have to step through maybe 1000 steps to trigger this, and then I'd have to do it again just to inspect the variables.
Let's start looking into ways to debug this.. like valgrind.
https://www.valgrind.org/info/tools.html
Oh wow! did not know about cachegrind which allows me to see how my application uses the cache, that is so cool!
Sadly, Mac Osx 10.14 is not supported!
Okay so what else? Well just came across a flag in gcc called "-fsanitize=address"
Which yields:
AddressSanitizer:DEADLYSIGNAL
=================================================================
==53287==ERROR: AddressSanitizer: SEGV on unknown address 0x000000000000 (pc 0x000105bbc161 bp 0x7ffeea012630 sp 0x7ffeea012350 T0)
==53287==The signal is caused by a READ memory access.
==53287==Hint: address points to the zero page.
#0 0x105bbc160 in print_node markdown_compiler.c:623
#1 0x105bbd2df in print_node markdown_compiler.c:686
#2 0x105bbc6cc in print_node markdown_compiler.c:639
#3 0x105bbd2df in print_node markdown_compiler.c:686
#4 0x105bbd2df in print_node markdown_compiler.c:686
#5 0x105bbd2df in print_node markdown_compiler.c:686
#6 0x105bbd2df in print_node markdown_compiler.c:686
#7 0x105bbd2df in print_node markdown_compiler.c:686
#8 0x105bbd2df in print_node markdown_compiler.c:686
#9 0x105bbf6f7 in markdown_compiler markdown_compiler.c:825
#10 0x105bbfe2e in main main.c:66
#11 0x7fff71d013d4 in start (libdyld.dylib:x86_64+0x163d4)
==53287==Register values:
rax = 0x7878787878787878 rbx = 0x00007ffeea014080 rcx = 0x0f0f1f0f0f0f0f0f rdx = 0x0000100000000000
rdi = 0x0000000000000000 rsi = 0x0000000105bc0700 rbp = 0x00007ffeea012630 rsp = 0x00007ffeea012350
r8 = 0x0000000000000001 r9 = 0x000000000000000c r10 = 0x00001fffdd405918 r11 = 0x0000000000000004
r12 = 0x00007ffeea045000 r13 = 0x00001fffdd40280c r14 = 0x00007ffeea02c820 r15 = 0x00007ffeea02c860
AddressSanitizer can not provide additional info.
SUMMARY: AddressSanitizer: SEGV markdown_compiler.c:623 in print_node
==53287==ABORTING
/bin/bash: line 1: 53287 Abort trap: 6 ./main
I see that this is this line:
switch(node->type){So I wonder.. am I not initializing type to null?
But before that, I'd really love to be able to read the register values better.
Some things I see:
rax = 0x7878787878787878
Why 78787878..?
rbx = 0x00007ffeea014080
This looks like a memory address?
rcx = 0x0f0f1f0f0f0f0f0f
Another pattern.. What's up with that?
rdx = 0x00001000 0000 0000
This looks more sensible. It's either the number 2048, or some flag I imagine?
rsi = 0x0000000105bc0700
Not sure what this is..
rbp = 0x00007ffeea012630
Ah the base pointer reveals that I was right about the b register (rbx), both are memory addresses fairly close to each other. Only off by 6,736. (By the way, if you open Mac osx calculator app, there is an amazing programmer calculator hidden there! So useful.)
rsp = 0x00007ffeea012350
And the stack pointer lets us know how much memory is on the stack by showing the difference between the base pointer and the stack pointer. 736 bits.. 92 bytes? 11 words? Don't quote me on this... I may be confusing things..
I am curious how closely this matches.. Unfortunately, codeclap doesn't provide this level of introspection on registers..
r10 = 0x00001fffdd405918
r12 = 0x00007ffeea045000
r13 = 0x00001fffdd40280c
r14 = 0x00007ffeea02c820
r15 = 0x00007ffeea02c860
And some more menory addresses I'm assuming. Though some are high and some are low.
From my prior notes in memory, I know that memory looks like this:
HIGH stack (Descending in memory) \/
__ brk (break)
_/
heap (Ascending in memory) /\
bss (uninitialized variables, static int y;)
data (initialized variables, int x = 2;)
LOW text (instruction, code segment)
Not that that says a lot right now.. Though I am wondering why some of these registers are pointing to higher values.. Let's put them all side by side with their digital representations. In decending order, high to low.
r13 = 0x00001fffdd40280c 35183789090828 r10 = 0x00001fffdd405918 35183789103384 rsp = 0x00007ffeea012350 140732824363856 rbp = 0x00007ffeea012630 140732824364592 rbx = 0x00007ffeea014080 140732824371328 r14 = 0x00007ffeea02c820 140732824471584 r15 = 0x00007ffeea02c860 140732824471648 r12 = 0x00007ffeea045000 140732824571904Okay, so we can see how the stack pointer is decending in memory. I wonder what these other registers are pointing at, but I'm going to have to live with the mystery for now. Okay let's take a look at the assembly code to see if we can glean anything from that. Very sadly codeclap does not allow copying from the program.. Or at least it doesn't give me the ability to select anything.. So first, I want to see if I can tell what line of assembly this breaks down. Let's take a look at the assembly code and see if it matchs.. though it might now either.. maybe these values are different every time.. Hmm, maybe I should run this again and see if I get the same values.
==53600==Register values: rax = 0x7878787878787878 √ rbx = 0x00007ffee8ce2080 X rcx = 0x0f0f1f0f0f0f0f0f √ rdx = 0x0000100000000000 √ rdi = 0x0000000000000000 √ rsi = 0x0000000106ef26c0 X rbp = 0x00007ffee8ce0530 X (but same difference) rsp = 0x00007ffee8ce0230 X (but same difference) r8 = 0x0000000000000001 √ r9 = 0x000000000000000c √ r10 = 0x00001fffdd19f518 X r11 = 0x0000000000000004 √ r12 = 0x00007ffee8d13000 X r13 = 0x00001fffdd19c40c X r14 = 0x00007ffee8cfa820 X r15 = 0x00007ffee8cfa860 XOkay so it looks like anywhere memory address is referenced, it's different each time. What about with -fno-pie -no-pie?
rax = 0x7878787878787878 √ rbx = 0x00007ffeefbcb080 √ rcx = 0x0f0f1f0f0f0f0f0f √ rdx = 0x0000100000000000 √ rdi = 0x0000000000000000 √ rsi = 0x00000001000096c0 √ rbp = 0x00007ffeefbc9530 √ rsp = 0x00007ffeefbc9230 √ r8 = 0x0000000000000001 √ r9 = 0x000000000000000c √ r10 = 0x00001fffddf7c718 √ r11 = 0x0000000000000004 √ r12 = 0x00007ffeefbfc000 √ r13 = 0x00001fffddf7960c √ r14 = 0x00007ffeefbe3820 √ r15 = 0x00007ffeefbe3860 √That works perfect! Cause I'm turning off position independent code (PIE), which prevents address space layout randomization (ASLR) from occuring, a security feature. This is super helpful for debugging. ...except that looking at codeclap isn't so helpful, the problem is, very rarely do we ever see any simple assembly code, that just moves a value into a register. More often we're putting values into the memory addresses that are stored inside a register. So not much luck here. Well that was an entertaining diversion!
==53860==ERROR: AddressSanitizer: SEGV on unknown address 0x000000000000 (pc 0x000100005051 bp 0x7ffeefbc9530 sp 0x7ffeefbc9230 T0) ==53860==The signal is caused by a READ memory access. ==53860==Hint: address points to the zero page.Okay let's look at this. Maybe it will be helpful. Oh cool! I see that this points to an assert I just created.. Let's get rid of that and continue.
==53916==ERROR: AddressSanitizer: SEGV on unknown address 0x000000000000 (pc 0x000100005161 bp 0x7ffeefbc9630 sp 0x7ffeefbc9350 T0) ==53916==The signal is caused by a READ memory access. ==53916==Hint: address points to the zero page.
movb (%rcx), %silThis is the line! Now I imagine the zero page is just the memory address zero. No. The Zero page starts at address zero, but it could be a bit higher, depending on the page size. So this is reading from the address of %rcx, and it's hitting the zero page.. That doesn't tell me too much.. But I do think that when we read from node->type, we're getting an invalid address. Ah yeah. Just by accessing node->type we get an invalid. Let's take a look at this. I see. It is crashing here:
# This is a header
You could be typing **something**.
Right at the end of "something".
I think the problem is node->next is not null when it should be null.
bingo:
node->next 0x7878787878787878And it's interesting that that matches my rax:
rax = 0x7878787878787878Wow! I just learned something! For the function:
void print_node(char * t, struct Node *node, int indent) {
Here's the memory address of each variable:
t 0x7ffeefbe3860 node 0x7878787878787878 indent 0x7ffeefbc88c0
r15 = 0x00007ffeefbe3860 rax = 0x7878787878787878 rsp = 0x00007ffeefbc88a0r15 holds the first argument rax holds the second argument And the third argument, which is passed by value, ends up on the stack, just 32 bytes up in memory, meaning it was placed there, and then the stack pointer decreased by 32 bytes. Makes sense! And so now I can easily know without printfs what the arguments of the function are when it dies, and I can easily verify when the node is 0 or a valid memory address, vs. when it is a bunch of garbage. This looking through my code I realize that I was allocating memory to next if it needed it, but I was not setting it to zero if it was not needed.
void parse_any(struct Node *node) {
parse_rules(node);
if (!is_deadend(g.tokens->type)) {
node->next = allocate(sizeof (struct Node));
parse_any(node->next);
}
else {
// THE SOLUTION!
node->next = 0;
}
}
So that is done! I can't believe how awesome -fstanitize=address is.. How have I never heard of this before? It comes free with gcc!
These are the kinds of challenges that really make me feel like I'm building skills as a programmer. A hanging curiocity for me is learning more about the order registers are used for functions.
Callee-saved registers (non-volatile / call preserved registers) - When a caller makes a procedural call it can expect that those registers will hold the same value after the callee returns.
call preserved: r12-r15, rbx
rax is a temp register / return value.
This makes sense in the context of my code, since char * t, is used everywhere, where as "next" isn't used after the function is called. Anyways..
Now we can get back to generating more files.
I guess we should check to make sure the files generated are correct..
It works!
Okay, time to create one that has a sidebar navigation.
Next up:
• Evaluate what my config file will look like that's going to generate all these links and titles.. What should it include?
Okay, back to this.. I want to wrap this up as soon as possible. (couple hours later) Okay it's done. I did it. It's not what I wanted at the beginning, but it's functional enough to get some stuff done and it's easy to customize. So what are the take aways here? I think I'm learning something about the size of a project I want to take on. I underestimated the amount of work that would be needed for the completion of this project! Had I known, I probably wouldn't have attempted it. And also, after a certain amount of time, priorities change. I don't want to get in the habit of unfinished projects, so it's not like a project should be stopped once it's no longer as important, but the length of a project should take into account how things change. This project was created to satisfy an itch, and to learn a lot, not to accomplish something great. So it satisfied these goals. 1. Start with the inside of the problem first. 2. Set yourself up so that you can easily rush a project to completion by cutting corners. 3. Stand where you can see the two walls of reality. 4. Assume a project will be a lot more complex than you think it is. I am done. Really embarassing, these are the kind of I-told-you so issues that people expect you to run into! I've got to get to the bottom of this and really deeply understand this, so that I can create an assert that will cause it to crash in all future programs I write.
[...later]
Hmmm... This one was a weird string related error.
broken code:
Really embarassing, these are the kind of I-told-you so issues that people expect you to run into! I've got to get to the bottom of this and really deeply understand this, so that I can create an assert that will cause it to crash in all future programs I write.
[...later]
Hmmm... This one was a weird string related error.
broken code:
Conclusion
A quote from Jonathan Blow: "having to code directly to metal, there's an element of reality there. Caring what something looks likes to the end user is a different wall of the room of reality. Seeing both of those walls at the once is useful I think..." I really value this point. This project has taught me something deeper than the low level particulars. When I take on a project, deep low level knowledge is not the only bit of knowledge to gain - there is also the knowledge of coding something large - how to hold and arrange that complexity in the simplest way possible. When focusing on low level details, there is less attention and time devoted to the high level details. It's as if you can see one wall of reality, but that's it. Now one might use this as an argument for using an engine that abstracts away all the low level details, so you can focus exclusively on the end user, but now only the other wall of reality is visible. The consequence of the former problem, is that it takes a long time to deliver, and perhaps you've gotten far away from the concerns of the user. The consequence of the latter, is that later on in development, you have little ability to fine tune your product, and so the end user experience is mediocre, which is the world in which most software operates. Mike Acton says that the kind of abstraction that is good, is the kind that is a utility, something that can be easily ripped out and replaced.. You can operate on the thing underneith the abstraction layer (like ripping out a light switch, and crossing two wires to operate the switch), where as the bad kind requires "graduating" to a different level. Perhaps like some kind of box which digitally handles switching lights on and off. Basically, you can't tear it out, you'd have to carefully construct your own device with all the connectors just so, that handles the turning on and off lights. My next project will be to balance this as much as I can. I will use simple single header libraries to expedite my process, and only go about writing stuff at a lower level than that if it truly is a performance bottleneck, or if there are truly no available libraries I trust. I am taking a step back from approaching the next project in the Handmade Hero way. I know it wasn't Casey's intention that everyone write everything themselves, only that it is possible, and that there is a better way of writing code than the methods which dominate the industry. I will take that lesson with me, and utilize all I've learned while working in the sweet spot between low level, and end user, standing in the center of the room, with both walls of reality in sight. Another quote from Jonathan Blow: "you can't be that far from the cpu, but if you think every little cpu thing is super interesting and rathole on doing the optimal job on that thing you will never ship a large piece of software" There is so much important work to be done. I still care deeply about the low level code, but the work that I want to be doing.. If I focus on the low level code and neglect delivering to the end user, then I will be proving out the naysayers of the handmade movement. As handmade coders, we must deliver - this strikes me as a central tension in the work. To break free of the toxic wave of programming, to care about performance and quality, and also SHIP.Okay, back to this.. I want to wrap this up as soon as possible. (couple hours later) Okay it's done. I did it. It's not what I wanted at the beginning, but it's functional enough to get some stuff done and it's easy to customize. So what are the take aways here? I think I'm learning something about the size of a project I want to take on. I underestimated the amount of work that would be needed for the completion of this project! Had I known, I probably wouldn't have attempted it. And also, after a certain amount of time, priorities change. I don't want to get in the habit of unfinished projects, so it's not like a project should be stopped once it's no longer as important, but the length of a project should take into account how things change. This project was created to satisfy an itch, and to learn a lot, not to accomplish something great. So it satisfied these goals. 1. Start with the inside of the problem first. 2. Set yourself up so that you can easily rush a project to completion by cutting corners. 3. Stand where you can see the two walls of reality. 4. Assume a project will be a lot more complex than you think it is. I am done.
Update 7.3.2020:
Even though this project ended abruptly, I'm rather happy with it! I feel like I got it to a place where it's easy to tweak and extend, and from now on I'll just make small incremental changes to it as I'm writing. In this way, the blog and platform can evolve together.Update 7.7.2020:
Loving this project now - it makes daily blogging a snap. But just ran into a huge issue of the worst kind. A non-crashing bug which causes html to come out really weird:
Really embarassing, these are the kind of I-told-you so issues that people expect you to run into! I've got to get to the bottom of this and really deeply understand this, so that I can create an assert that will cause it to crash in all future programs I write.
[...later]
Hmmm... This one was a weird string related error.
broken code:
t[temp_i] = value_char; ++temp_i; ++value_i;Working code:
char temp_str[2]; temp_str[0] = value_char; temp_str[1] = '\0'; strcat(t, temp_str); ++value_i;I see. The reason this broke is because elsewhere, I rely on the string ending in a '\0', but here I was just putting characters one after the other based on the index.. sprintf killed me here. I'm seeing how painful dealing with strings can be. They tend to explode. The convenience functions that deal with strings in C have betrayed me everytime. Though I'll also note, this was more difficult to really see because I was using #define function, which kind of obscured what I was doing. Even the slightest distance from the actual code and we get into trouble! I see - my meta programming saves me from overflowing memory, but it does not save me introducing a bug where the length of a string is wrong. It has no way of knowing if that \0 is in the right place or not. Maybe I should just pass in an index.. But this is so annoying.. I am curious if this warrants switching to Odin or Zig.. would that remove these very painful moments? Maybe creating a string struct, and writing a few helper functions around that would help.. No - the issue is sprintf is really useful, but I often can't use it how I'd like.. slight cleanup:
sprintf(&t[strlen(t)], "%c", value_char);
++value_i;
Got confused about referencing t properly, but then figured it out.
If there was a method called strcatf, that would help!
I guess I can create that though.. but that requires a variadic function which is a bit annoying.
Whatever, I'm done with this for now. I'd like to to do some simple projects with these other languages, but I think I'll continue with C for now and try to figure out a way to get things really solid with strings.
Perhaps I just create a rule - no more manually adding on to a string - null terminated strings at all times?
[...later]
Wow. I just added an automatically created navigation to every page - this was possible thanks to the markdown compiler. Every time I create a HEADER node, I add it to a list of links, and generate html from that later and drop that in where I used to put the manually created navigation.
When you start working at a lower level, your brain begins to see new ways of approaching a problem.